pacman::p_load(sjlabelled, dplyr, #Manipulacion de datos stargazer, #Tablas sjmisc, # Tablas summarytools, # Tablas kableExtra, #Tablas sjPlot, #Tablas y gráficos corrplot, # Correlaciones sessioninfo, # Información de la sesión de trabajo ggplot2) # Para la mayoría de los gráficos
2 Cargar bases de datos
Cargamos ambas bases de datos desde internet
Code
load(url("https://github.com/Kevin-carrasco/R-data-analisis/raw/main/files/data/latinobarometro_total.RData")) #Cargar base de datosload(url("https://github.com/Kevin-carrasco/R-data-analisis/raw/main/files/data/data_wvs.RData")) #Cargar base de datos
Para trabajar con ambas bases, agruparemos las variables de interés por país, por lo que ya no trabajaremos directamente con individuos.
Code
context_data <- wvs %>%group_by(B_COUNTRY) %>%# Agrupar por paíssummarise(gdp =mean(GDPpercap1, na.rm =TRUE), # Promedio de GDP per capitalife_exp =mean(lifeexpect, na.rm =TRUE), # Promedio esperanza de vidagini =mean(giniWB, na.rm =TRUE)) %>%# Promedio ginirename(idenpa=B_COUNTRY) # Para poder vincular ambas bases, es necesario que la variable de identificación se llamen igualcontext_data$idenpa <-as.numeric(context_data$idenpa) # Como era categórica, la dejamos numéricaproc_data <- proc_data %>%group_by(idenpa) %>%# agrupamos por paíssummarise(promedio =mean(conf_inst, na.rm =TRUE)) # promedio de confianza en instituciones por país
3 Unir bases de datos
Para vincular nuestras bases de datos existen múltiples opciones, la primera es ‘merge’ de R base y las siguientes tres vienen desde dplyr: ‘right_join’, ‘full_join’ y ‘left_join’. Cada una tiene sus propias potencialidades y limitaciones y dependerá de cada caso cuál usemos
3.0.1 Probemos merge
Code
data <-merge(proc_data, context_data, by="idenpa")
sjmisc::descr(data,show =c("label","range", "mean", "sd", "NA.prc", "n"))%>%# Selecciona estadísticoskable(.,"markdown") # Esto es para que se vea bien en quarto
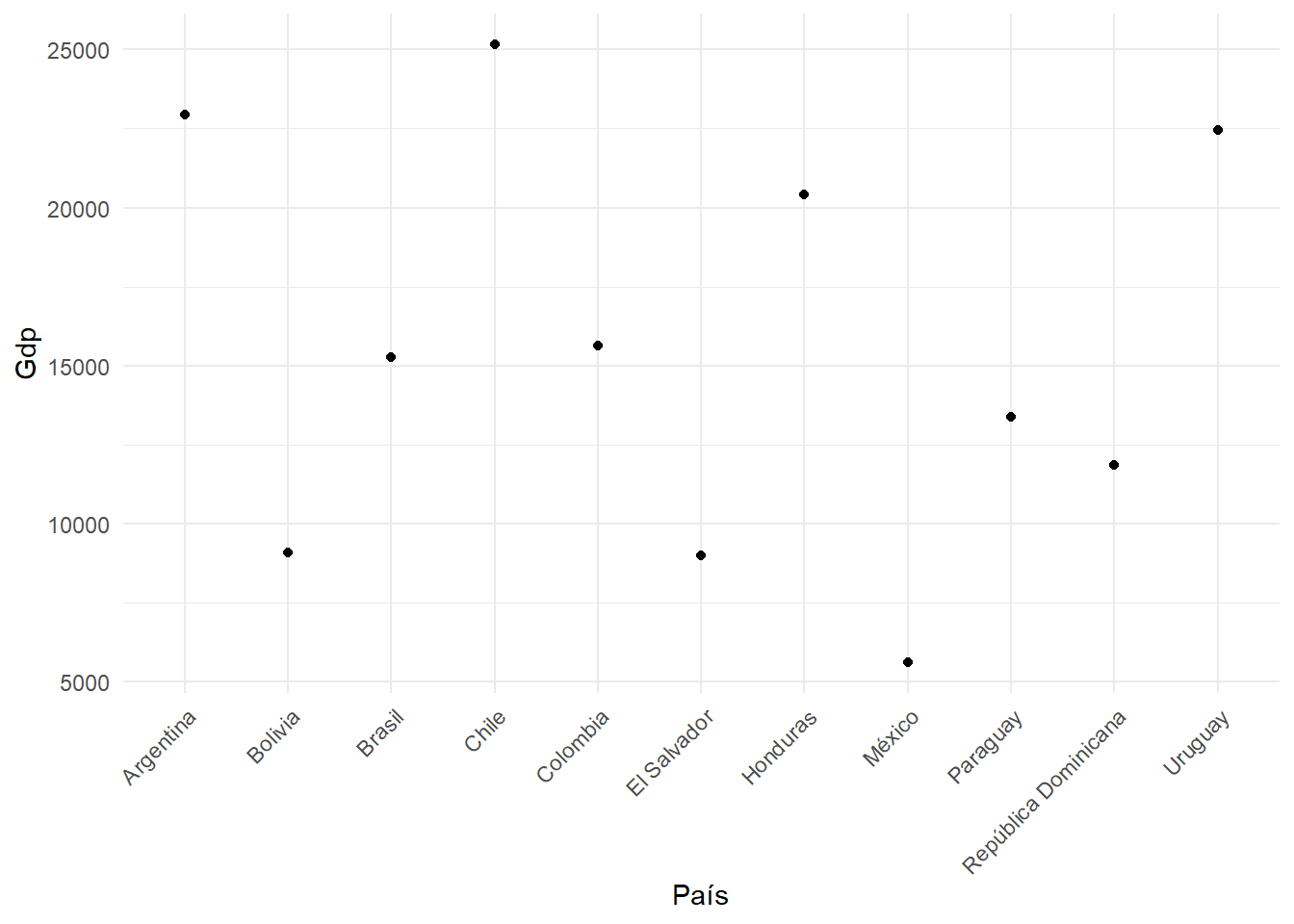
ggplot(data, aes(x = idenpa, y = gdp)) +geom_point() +labs(x ="País", y ="Gdp") +theme_minimal()+theme(axis.text.x =element_text(angle =45, hjust =1))
Code
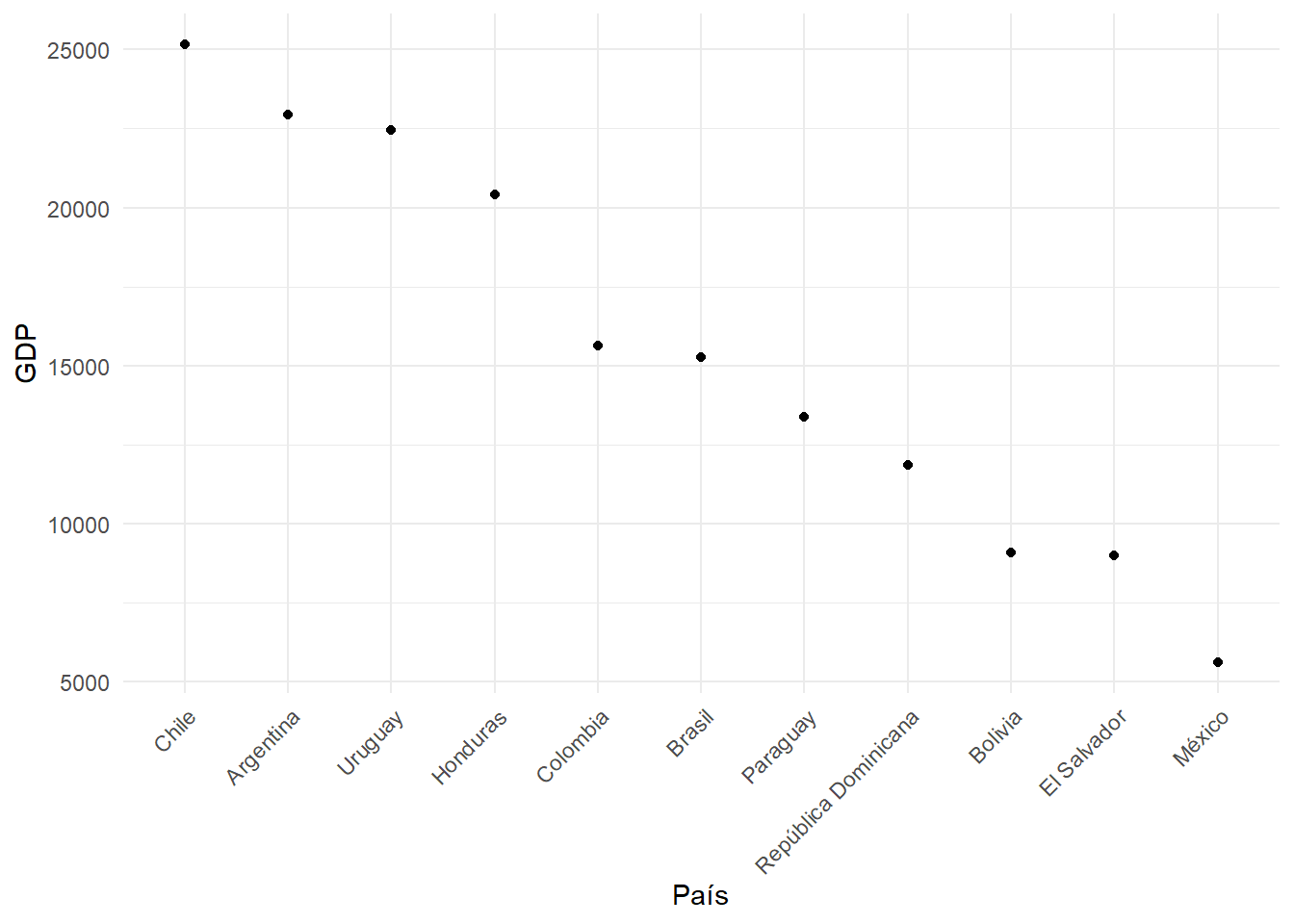
data_sorted <- data %>%arrange(desc(gdp))ggplot(data_sorted, aes(x =factor(idenpa, levels = idenpa), y = gdp)) +geom_point() +labs(x ="País", y ="GDP") +theme_minimal() +theme(axis.text.x =element_text(angle =45, hjust =1))
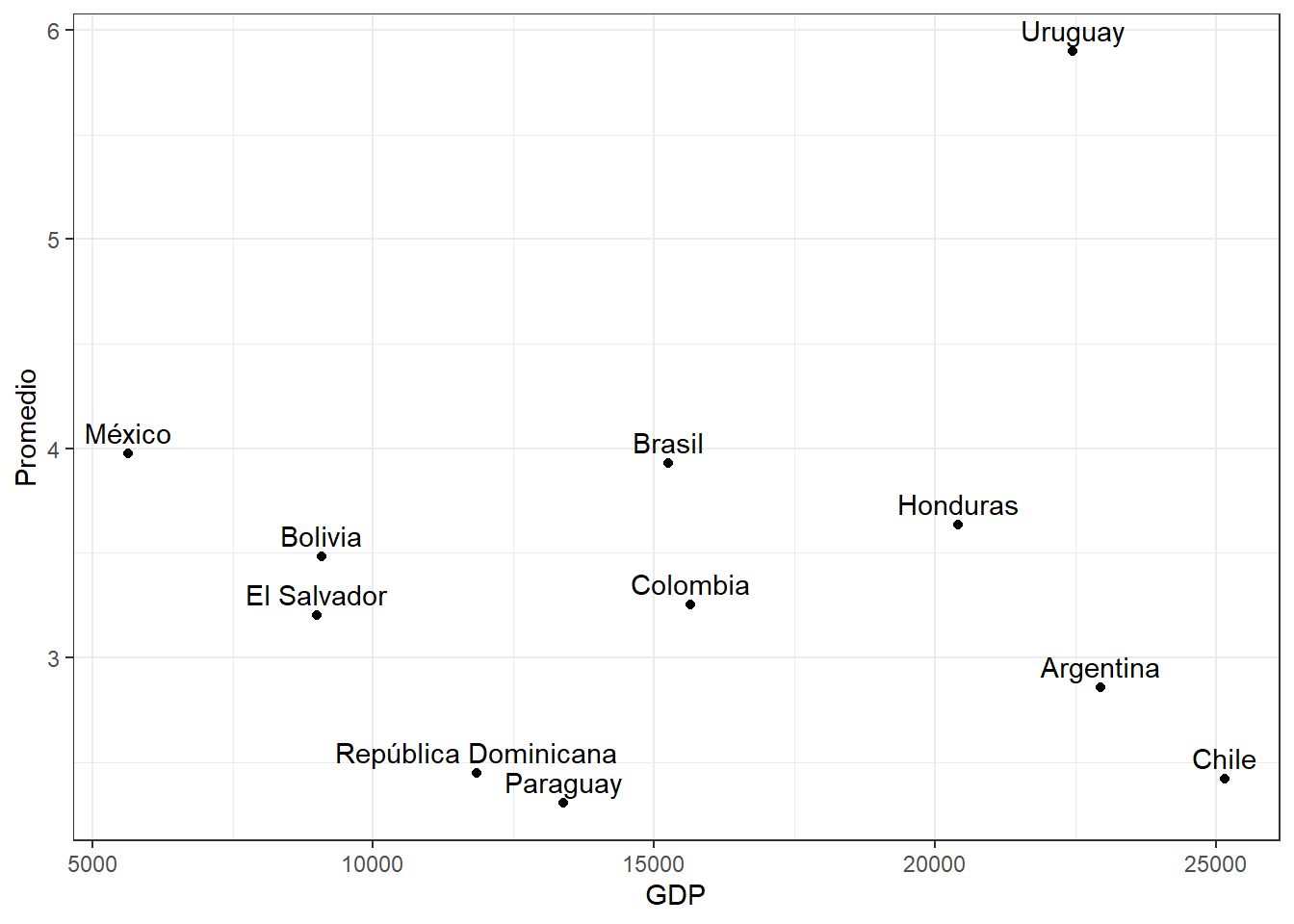
Y comparar el promedio de confianza en instituciones según producto interno bruto por país?
Code
data %>%ggplot(aes(x = gdp, y = promedio, label = idenpa)) +geom_point() +geom_text(vjust =-0.5) +labs(x ="GDP", y ="Promedio") +theme_bw()
Source Code
---title: "Práctico 5"author: "Kevin Carrasco"format: html: toc: true number-sections: true---# Cargar paquetes```{r}pacman::p_load(sjlabelled, dplyr, #Manipulacion de datos stargazer, #Tablas sjmisc, # Tablas summarytools, # Tablas kableExtra, #Tablas sjPlot, #Tablas y gráficos corrplot, # Correlaciones sessioninfo, # Información de la sesión de trabajo ggplot2) # Para la mayoría de los gráficos```# Cargar bases de datosCargamos ambas bases de datos desde internet```{r}load(url("https://github.com/Kevin-carrasco/R-data-analisis/raw/main/files/data/latinobarometro_total.RData")) #Cargar base de datosload(url("https://github.com/Kevin-carrasco/R-data-analisis/raw/main/files/data/data_wvs.RData")) #Cargar base de datos```Para trabajar con ambas bases, agruparemos las variables de interés por país, por lo que ya no trabajaremos directamente con individuos.```{r}context_data <- wvs %>%group_by(B_COUNTRY) %>%# Agrupar por paíssummarise(gdp =mean(GDPpercap1, na.rm =TRUE), # Promedio de GDP per capitalife_exp =mean(lifeexpect, na.rm =TRUE), # Promedio esperanza de vidagini =mean(giniWB, na.rm =TRUE)) %>%# Promedio ginirename(idenpa=B_COUNTRY) # Para poder vincular ambas bases, es necesario que la variable de identificación se llamen igualcontext_data$idenpa <-as.numeric(context_data$idenpa) # Como era categórica, la dejamos numéricaproc_data <- proc_data %>%group_by(idenpa) %>%# agrupamos por paíssummarise(promedio =mean(conf_inst, na.rm =TRUE)) # promedio de confianza en instituciones por país```# Unir bases de datosPara vincular nuestras bases de datos existen múltiples opciones, la primera es 'merge' de R base y las siguientes tres vienen desde dplyr: 'right_join', 'full_join' y 'left_join'. Cada una tiene sus propias potencialidades y limitaciones y dependerá de cada caso cuál usemos### Probemos merge```{r}data <-merge(proc_data, context_data, by="idenpa")``````{r}data <- data %>%mutate(idenpa =as.character(idenpa)) %>%mutate(idenpa =case_when( idenpa =="32"~"Argentina", idenpa =="68"~"Bolivia", idenpa =="76"~"Brasil", idenpa =="152"~"Chile", idenpa =="170"~"Colombia", idenpa =="188"~"Costa Rica", idenpa =="214"~"Cuba", idenpa =="218"~"República Dominicana", idenpa =="222"~"Ecuador", idenpa =="320"~"El Salvador", idenpa =="340"~"Guatemala", idenpa =="484"~"Honduras", idenpa =="558"~"México", idenpa =="591"~"Nicaragua", idenpa =="600"~"Panamá", idenpa =="604"~"Paraguay", idenpa =="858"~"Uruguay", idenpa =="862"~"Venezuela"))data$gdp <-as.numeric(data$gdp)data$gdp[data$gdp==0] <-NAdata <-na.omit(data)```# Visualizaciones## Descriptivos```{r}sjmisc::descr(data,show =c("label","range", "mean", "sd", "NA.prc", "n"))%>%# Selecciona estadísticoskable(.,"markdown") # Esto es para que se vea bien en quarto```## otra opción```{r}view(dfSummary(data, headings=FALSE))```# Gráficos```{r}ggplot(data, aes(x = idenpa, y = gdp)) +geom_point() +labs(x ="País", y ="Gdp") +theme_minimal()+theme(axis.text.x =element_text(angle =45, hjust =1))``````{r}data_sorted <- data %>%arrange(desc(gdp))ggplot(data_sorted, aes(x =factor(idenpa, levels = idenpa), y = gdp)) +geom_point() +labs(x ="País", y ="GDP") +theme_minimal() +theme(axis.text.x =element_text(angle =45, hjust =1))```Y comparar el promedio de confianza en instituciones según producto interno bruto por país?```{r}data %>%ggplot(aes(x = gdp, y = promedio, label = idenpa)) +geom_point() +geom_text(vjust =-0.5) +labs(x ="GDP", y ="Promedio") +theme_bw()```